Jenkins: Documenting Data with Metadata
Data without associated annotation and metadata (documentation describing the data) is of little lasting value 1. It is imperative that each dataset used for processing and analysis includes sufficient metadata so that its origin, content, and processing state are clearly understood. It is only then that data becomes truly useful and trustworthy.
A friend of mine has called well-annotated data ‘civilized data’, others have called it ’tidy data’ 2.
Here I establish some metadata vocabulary for Jenkins data science applications, so we can continue future blogs with a common vocabulary.
Note: In the context of this discussion I will use the term annotation and metadata almost interchangeably.
Metadata Origins
Research application metadata is either automatically or manually created and associated with primary data. Automatic metadata can be added by instruments or software systems that acquire scientific measurements, and observations. However, many critical metadata can only be provided by a human familiar with the design, samples, data, and methods involved in the generation of experimental data.
A familiar example of these two classes of metadata can be found in stored digital images. A digital camera records along with each digital image a wealth of acquisition metadata such as an auto-generated file name, the camera model, a time-stamp, exposure, f-stop and even geocoding information. However, only a human can annotate the image with metadata that are really useful for other humans to search and find a picture in a collection. In this situation a human would have to annotate pictures with metadata such as people’s names, occasion, etc.
Measurements from a well-conducted scientific study should generated data and associated metadata that is relevant and if possible standardized 1. 
Figure 1 : Scientific datasets should be annotated with relevant metadata that documents and describes the data.
In life sciences, there are many cases, where data annotation is left to an expert data curator (and more recently to machines with artificial intelligence), but that is typically a last ditch effort to salvage a dataset that was improperly annotated in the first place. I will not discuss these issues here, but I will introduce you to some of the strategies that we can use with Jenkins and R to generate ‘civilized data’.
Jenkins, Builds, Data and Metadata
The BioUno project is championing the use of [Jenkins as a platform for data-science]({{ site.url }}/2016/03/07/Creating-a-Jenkins-Data-Science-Platform) and research computing. In this context this blog series will focus on how we deal with datasets and their metadata when they are processed by Jenkins projects and stored as Jenkins artifacts.
Data Source Builds
When a Jenkins build generates one or more dataset artifacts we call it a data source build. Data source build artifacts are typically used by downstream builds as input artifacts for downstream analysis and processing. Data source builds themselves can vary, but in general they act to import, process or transform data.
The files produced by a data source build are primary datasets that we can use as input for additional processing algorithms
Data source builds are also responsible for generating the primary metadata associated with the data source artifacts.
Automatic Metadata for a Data Source
Each data source artifact is automatically associated with a rich set of Jenkins build metadata . This is similar to a digital camera recording automated metadata. Jenkins records build metadata in the corresponding build.xml file and include useful details such as a build status flag (success/failure), a unique build identifier, user, version of the processing script as well as the options and parameter values that were used in the build.
Manual Metadata for a Data Source
In reality, build metadata can easily extend unlike the limited set of automated metadata that a camera can record. During a freestyle build users can not only select analysis parameters, but can also also enter useful annotation that can extend and supplement the auto-generated metadata. Anything captured on the job build form as a build parameter,is recorded in the build.xml and remains associated with the build artifacts (datasets, results).
Dynamic Metadata for a Data Source
Finally, a data source build can dynamically generate new metadata about the structure and format of the data source artifact. For tabular data this can for example include the number of rows and columns in the dataset and the type of the values in each column (numeric, character date etc.) Useful summary statistics can also be generated and stored as data source metadata.
Metadata-Only Builds
Not every build generates a data source artifact. Some builds process the input data with the goal of deriving new information from it. I’ll refer to these as metadata-only builds .
To illustrate, suppose you are analyzing trends in the price of a company stock 3. The data source artifact may consist of a dataset of a company’s stock performance (daily open,close high low stock price) over the past year. The first step is to identify the overall trend. We perform this using a trend-analysis Jenkins job, then we use a second high-low analysis Jenkins job to analyze the 52-week high/low market stock price. The trend and calculated 52-week high/low prices from these build are just additional metadata to be associated with the input data source. 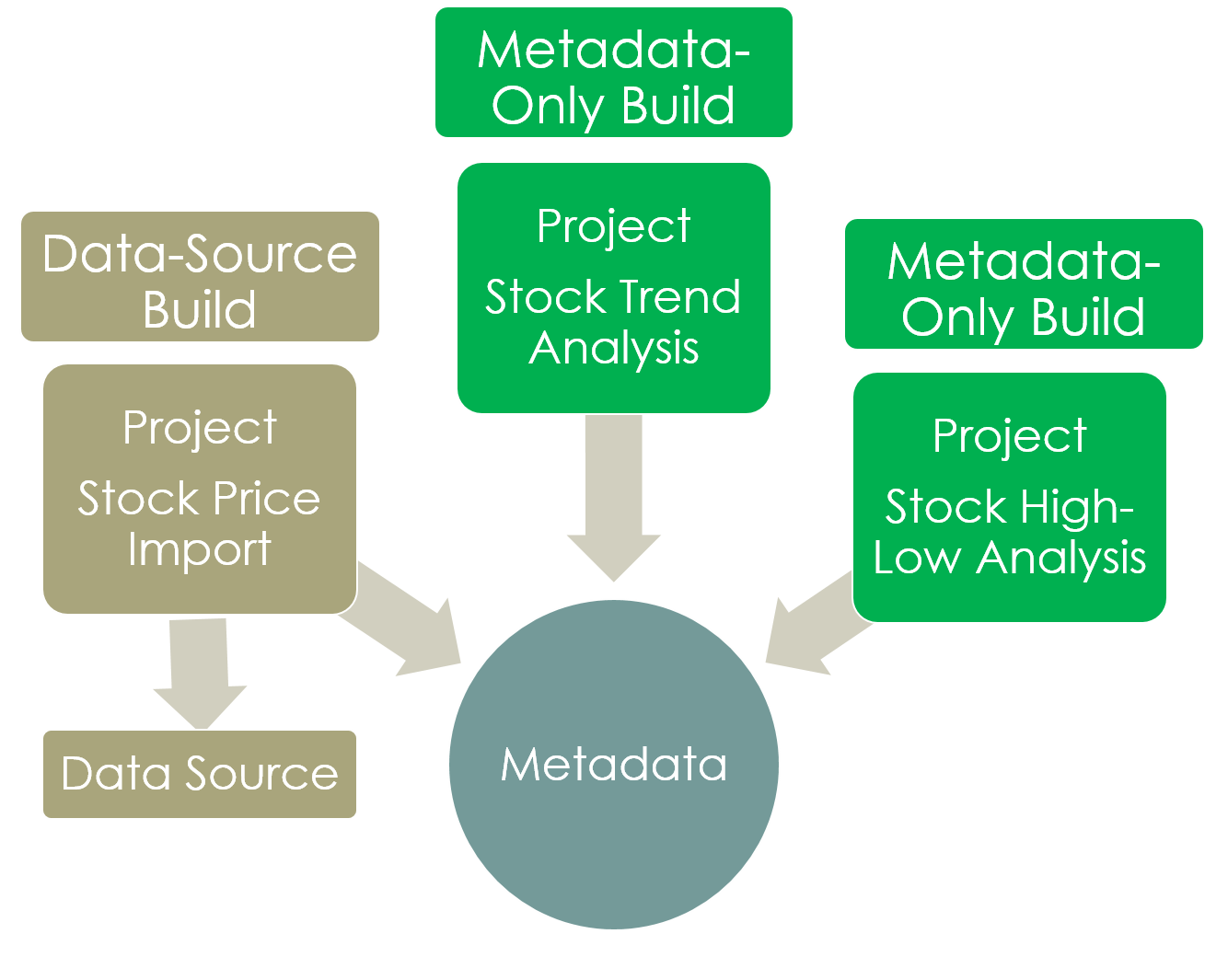 Figure 2 : An example illustrating data source and metadata-only builds. Data source builds generate dataset(s) and metadata. Metadata-only builds generate metadata related to their input dataset(s).
Figure 2 : An example illustrating data source and metadata-only builds. Data source builds generate dataset(s) and metadata. Metadata-only builds generate metadata related to their input dataset(s).
Maintaining Data-Metadata Relationships in Jenkins
Metadata-only builds have to address a Jenkins ‘operational’ challenge , how to relate the input data source to the generated metadata artifacts. While a single Jenkins build has a well established input and output artifacts and metadata relationship, there is no built-in Jenkins mechanism for maintaining these relationships across various jobs and builds . The issue gets further complicated when one needs to analyze the same data source iteratively and in a non-linear manner.
Metadata-only builds create artifacts that are not stored in the same build (or even project) as the input data source and this raises some important questions:
- How can metadata-only build artifacts associated to the input data?
- Can metadata-only build artifacts be easily referenced when one uses the input data source for another project build?
- Can related metadata artifacts scattered across multiple projects and builds be grouped with primary metadata of the data source?
These questions do not frequently arise in the context of Dev-Op Jenkins pipelines. In these pipelines, artifacts are related by ‘upstream and downstream’ job relationships established in pipeline designs that are typically serial and immutable in nature. In contrast, for research and data science Jenkins applications, we must establish artifact data and metadata relationships and maintain them as users analyze data in a non-linear and predictable fashion.
We need to address these issues using custom designs that still takes advantage of the Jenkins application model and capabilities. We will address this in a follow up blog.