Advanced Cross-Project Linking of Jenkins Artifacts
Introduction
In Documenting Data with Metadata we discussed how Jenkins lacks a built-in framework for relating arbitrary Jenkins projects, builds, and artifacts. This creates a challenge for linking data and metadata generated in independent builds.
Jenkins job and build configuration, parameters and artifacts are persisted as separate files on the server file system. When Jenkins starts, it builds an in-memory Jenkins object model from the XML configuration and build files of every project, as well as from the file structure of the ‘jobs’ folder. However, there is no dedicated RDBMS (relational database management system) backing up this Jenkins model, and no attempt is made to formally relate builds to each other. Once the server is shutdown, the object model is lost and needs to be rebuild from scratch on the next restart.
In this post, we will examine strategies for overcoming these limitations, and establishing build relationships that are important for data reuse, comprehension and provenance in research and data science applications.
Let’s summarize the build and artifact types we introduced in the previous post and recall the typical ways that metadata is generated:
| Build Type | Build Artifacts | Comment |
|---|---|---|
| Data-source | Data, Metadata | build generates primary data and metadata |
| Analysis | Data, Metadata | build generates derived data and potentially additional metadata |
| Metadata-only | Metadata | build associates user provided metadata to a data-source |
Metadata is generated by:
- Parsing the structure and content of a data-source artifact. For example we can parse the header and row count of a CSV data file
- Manual annotation (i.e. build) by a user. For example the user could define experimental controls, replicates and groups associated with a data-source
- An analysis (i.e. build) performed on the data-source. Such builds can analyze the structure of the data, identify outliers, or identify samples of interest
- A visualization analysis performed on the data-source. Such builds can produce interactive graphs that can help users interactively explore the data-source
We will focus on how to establish and use relationships (links) between the different build types and their artifacts. The format of the artifacts is irrelevant (it can be binary, CSV, java properties, XML, JSON, html etc.) .
Linking builds across jobs
Note that our discussion involves arbitrary, asynchronous builds and not those chained into a job pipeline, which Jenkins typically links with an upstream-downstream relationship. We are mostly concerned with freestyle, parametrized Jenkins projects, as they provide interactive build forms suitable for Jenkins research and data-science applications.
Nonetheless, the strategies we will discuss can be used in pipelined builds to generate required build links.
Relational builds in Jenkins
As is the case for a RDBMS, we need a common key to establish a relationship between any two builds (entities) in the Jenkins model.
For parametrized builds, Jenkins provides a run parameter type , that can be used to reference (link) the current build to a previous build of another project. The value of a run parameter is the absolute URL to the job build.
Composing a custom Run Parameter type
Luckily, Jenkins also provides a unique sequential key for each build, the BUILD_NUMBER . A composite key (composed of the JOB_NAME and the BUILD_NUMBER) is even more useful and creates a unique reference to a job build on the server.
We will call this composite and unique key a BUILD_KEY , and conveniently format it as JOB_NAME#BUILD_NUMBER a format that is easily parsed to identify the referenced Jenkins job and build.
When build keys are used as build parameters, they relate the current build to another (from the same or other project). In a future blog we will discuss how we can implement and enhance BUILD_KEY(s) using Active Choices parameters.
Note: When one uses pipeline compatible steps the Run Selector Plugin provides references to previous builds similarly to a ‘run parameter’.
Linking data-sources to their metadata artifacts
Links between data-sources and their metadata are modeled by a one-to-many relation as the same data-source is reused in one or more metadata generating builds. Also, such links typically exist across different Jenkins projects.
A build reference example
We will demonstrate linking a data-source build with a metadata build using an example.
Let’s assume that we have two data-source Jenkins projects (jobs), DSR_A and DSR_B, and a ANL analysis parametrized project that uses as inputs the artifacts generated from DSR_A and DSR_B.
A user configures an ANL build form by selecting the INPUT to be analyzed. The INPUT parameter is a selectable option referencing the available builds in DSR_A and DSR_B projects.
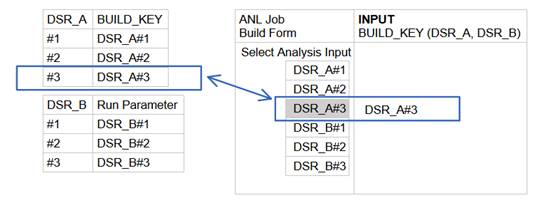
Figure 1 (above) displays DSR_A and DSR_B builds on the left and a schematic of the ANL build form on the right.
Assigning a DSR project BUILD_KEY to the value of the ANL INPUT parameter, introduces a unique DSR build reference in the ANL build configuration. This DSR BUILD_KEY will be stored in the build object model and can be used later to relate the ANL builds with the corresponding data-source build .
Note that each of the ANL builds, includes additional parameters (INPUT_DATA,PARAM01,PARAM02) and generates a new ARTIFACT as output.
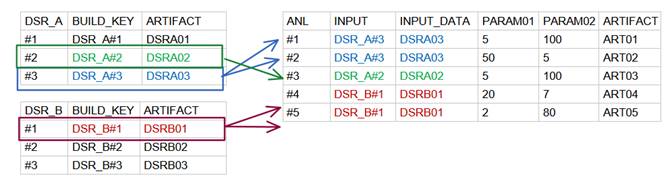
Figure 2 (above) The Jenkins builds model after several ANL builds. We have color-coded DSR builds and their corresponding ANL builds to highlight the one-to-many relation that exists between them.
We have successfully established a relational model between the DSR project builds (used as input) and the ANL analysis builds that reference them. The DSR (data-source) and ANL (metadata) projects are now linked via the ANL-INPUT parameter=DSR-BUILD_KEY relation.
Using BUILD_KEYS this relational model can be extended to more than one projects similarly to how one would build a relational model for an RDBMS using Unique and Foreign entity keys .
Discovering and using linked metadata
The value of any relational model is demonstrated in its ability to retrieve related entity data. We are now ready to use the Jenkins relational model of Figure 2 to reference any of the metadata builds (and artifacts) generated from a primary data-source. We will demonstrate this with an example.
Example: Referencing data-source metadata across projects
Let’s now assume that a second analysis project ANL_X uses as INPUT the same data-sources as ANL. Can the ANL artifacts be referenced from the ANL_X project (before or after ) a build starts?
The before option is of interest to research and data-science applications where if ANL results and data-source metadata could be referenced, they could provide useful information and guide the selection of ANL_X analysis parameters .
The relational model we established between DS and ANL projects supports the discovery and reuse of ANL metadata artifacts from ANL_X.
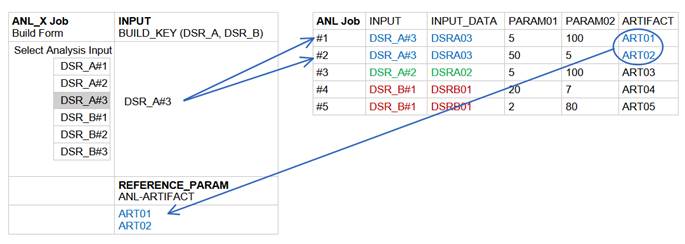
Figure 3 The ANL builds and artifacts can be retrieved from ANL_X through a lookup with the DS BUILD_KEY used as INPUT for both the ANL and ANL_X build.
As a result, during the configuration of an ANL_X build a user can retrieve and dynamically display the ART01 or ART02 artifacts of the corresponding ANL project.
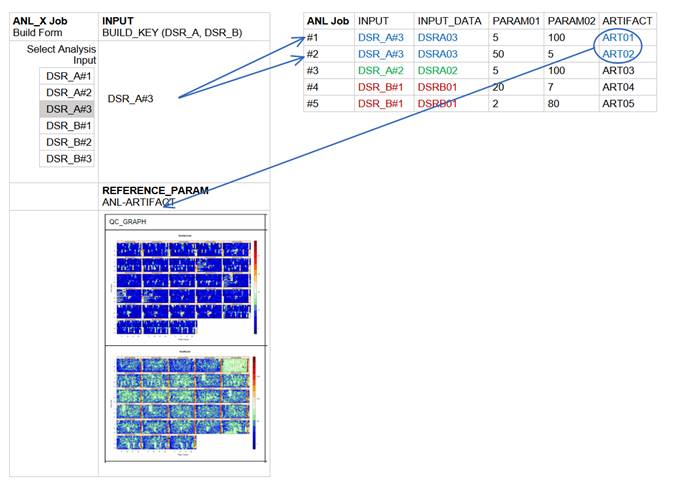
Figure 4 As the ANL_X build is configured, ANL artifacts relevant to the selected ANL_X INPUT can be retrieved and dynamically rendered in the ANL_X build form. The users gets additional insights and information on the INPUT source. This in turn can assist the user in selecting options for additional parameters of the ANL_X project.
Implementation: What’s next
In a follow-up blog entry I will give implementation details on the generation of BUILD_KEYS and their use in retrieving and displaying artifacts across Jenkins project builds. If you would like a head-start, become familiar with the Active Choices Jenkins Plugin. The power of Groovy, Jenkins Java API, javascript and dynamic HTML come together when we use this plugin to form a framework for dynamic, fully interactive UI that links and displays Jenkins artifacts across builds.